欢迎来到noYes游戏王国
网站导航
在上一篇文章中,小编为您详细介绍了关于《战歌竞技场法师最强阵容怎么搭配?法师最强阵容推荐[多图]》相关知识。本篇中小编将再为您讲解标题从设计到归因 - AB Test 实战心得。

前言 这是大Fei分享工作过程中,关于数据增长的系列文章,笔者(大Fei)在国内知名出海App任职数据负责人,有多年的相关工作经验,公众号的主笔与我亦师亦友,经常一同深究一些数据背后的逻辑,此次旨在分享一些自己的实战和分析经验,供大家参考,并与大家一起交流成长。 作为数据增长实战分享的第一篇,我先从个人认为最重要的AB Test实战开始分享,而分享过程中涉及到重要且无法展开的,未来会慢慢再与大家讨论和分享。甚至我会和大家讲到一些数据平台的使用玩法比如神策、Firebase等。 == 关于AB Test == 说到AB Test 大家都不会陌生,也是增长黑客概念流行以来非常热门的话题,我曾与业内经常做AB Test的朋友交流,也遇到过这类常见的问题
我们最可怕的不是不知道要开展AB 实验,而是明知道要开展,却不知道如何科学开展或开展后面对数据结果一脸茫然。 == 如何科学开展实验呢 == 首先,实验的过程可以简单分为三步
具体过程相信大家不会陌生,所以不会逐个介绍,下面我们重点聊聊整个过程可能常遇到的问题和经验教训,这也是我本次想分享的核心。 == 看似简单的实验设计,更需要重视 == 1、实验想法拿数据做支持 • 记住不要光拍脑袋不分析数据,这是提高实验成功率的有效途径,否则你将会承担更高的实验风险,要么实验没有效果,要么实验效果下滑,这些都是浪费资源的做法 • 公司不会有那么多时间和资源投入到一个又一个失败的实验方案中,因此想法很重要,但更重要的是参考、分析,为你的实验想法提供数据依据,拿数据说话 • 真实的情况是,我们完全可以拿数据否掉很多不靠谱的想法 • 由于本次分享的内容侧重点,这块内容以后的机会再分享 2、实验目标说清楚,写下来 • 清晰的实验目标能够让方案聚焦,也避免评估结果的相互扯皮 • 如果团队有人想要收入,有人想要留存,这往往打架的实验目标会造成后续的一系列麻烦 --- 经历: 我们曾遇到过一个实验对于收入的效果非常显著,但却损害了用户体验,导致用户认为应用收费性质过强而流失,但团队一致认为当前收入最重要,且通过数据验证了流失的用户均是较为低质的活跃用户,对长期留存来看并无意义,只是短期留存不好,DAU会下滑。 但团队中有人则认为前期的活跃用户更重要,不想流失用户和DAU下滑,这个就团队在前期没有确定一个一致的目标造成,最后的结果则是非常不欢,方案也没有上线,非常打击团队的信心。 我们不要总期待鱼和熊掌兼得,那是可遇不可求的,我们也正是一直在方案的利弊中,学会权衡并决策前行,这才是可贵的成长和经验,我们总要学会抛弃芝麻捡西瓜,把目标定下来,会更利于我们的决策。 --- 3、实验方案设计 • 清楚了解自己的实验目标,设定测试中想要测试的变量 • 尽量避免要评估的方案存在多变量的情况,控制唯一变量,有利于得到更多实验信息 • 分组设计会是另一个重点,我们放在后面来讲 --- 经历: 我们曾犯过这类错误,上线一个新的付费页面,但我们实验设计前期没有想清楚可以评估和实验的变量,导致我们只控制了展不展示该页面,但该付费页面我们换了新商品,更换了SKU组合,更换了商品的折扣属性,页面也放置在用户完成关键动作后出现。 不难想象,我们最终只得到了一个大而全的策略结果,而不知道页面里面的变化能起到的关键作用,因此我们浪费了一次机会,丢失了本可以获取的实验信息。 --- 这个过程就好比如下,同时修改了颜色和文案那样,我们无法知道颜色和文案分别的影响 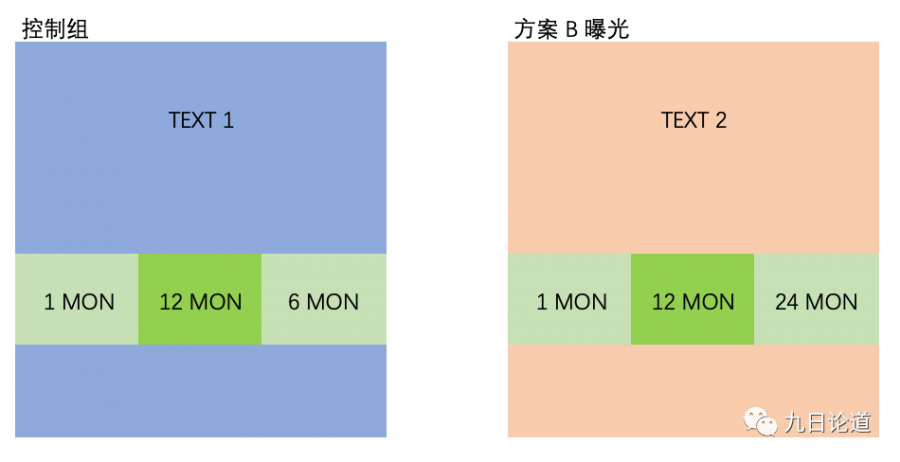
尽量不要做出这样的对比,在实验前想清楚,再想清楚,把你要评估的变量梳理清楚,这样再把变量拆开 如下: 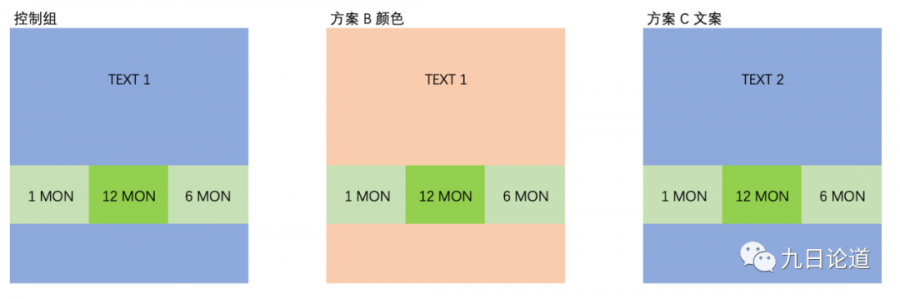
实验设计方案参考如下模板 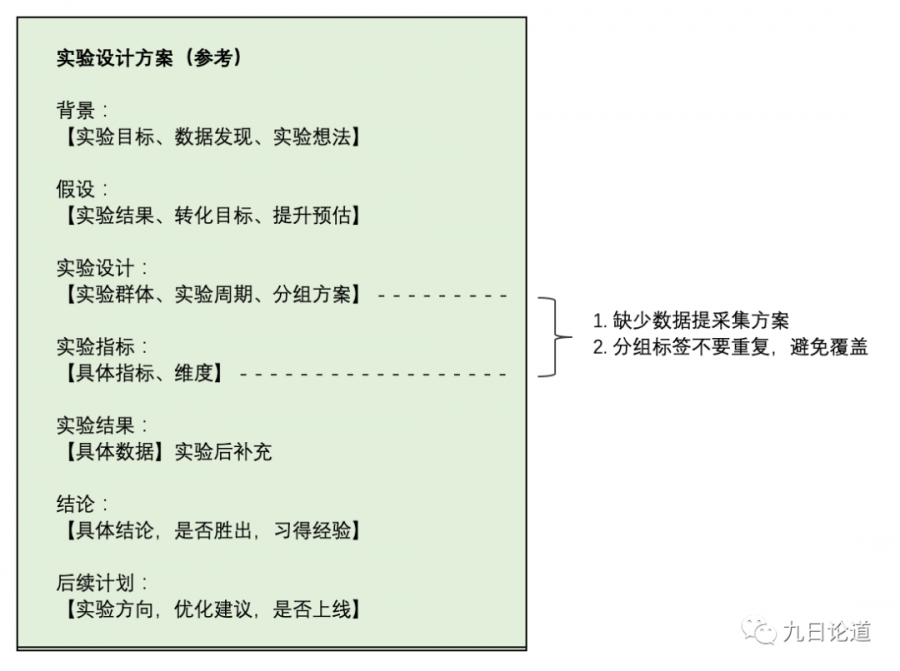
关于数据采集这块我就不做分享了,不是本次的重点,后续有机会我们再拿来分享 == AB实验工具 == 笔者使用过多个AB 工具,包括自研AB系统,Firebase等第三方支持AB 的工具,我总结了常见AB工具的几个特性,供大家今后需要的时候参考 当我们创建一个AB Test时,需要有: • 用户圈选:一般要求系统能够对目标实验群体做圈选,满足的用户进入AB Test,建议支持系统已有的用户属性,行为数据,用户标签等作为可选择维度,第三方工具则要求相关数据上报,需做好前期的实验设计和数据采集工作 • 实验灰度:假如你的实验不想影响所有用户,那么这个正是你所需要的,可以实现逐步放量,相对完善的AB工具均有此类选项,如Firebase • 配置项:一般指可以由后端自定义值的【远程配置】,例如:是否展示免费试用商品,就是一个【远程配置】 • 实验分组:任意增加多个分组,并为各组选择配置项,配置项的值,以及该组的样本比例 • 实验分组标记:每个创建的实验都建议为每个实验创建一个Track Tag,将分组名称作为值,如Test1_Control,Test1_VarB,Test1_VarC,然后作为一个用户的标签标记上,同时要避免标签数据被覆盖导致历史实验数据丢失 如果大家是做出海的App,Firebase是我优先推荐的,它是谷歌的产品,而且免费,但唯一不好是对国内支持不好,所以可以根据实验群体和场景选择哦。 当然最灵活的还是自研AB系统,但是这个需要一个较有经验的增长产品经理或增长数据分析师来参与比较好系统的设计和数据采集,这样才能较好确保系统的可用,否则仍会出现很多坑,下面我来讲一下我们团队在实验分组遇到过的问题。 == 实验分组 == 1、按照用户ID等属性计算随机值 我们团队一开始通过用户ID来实现简单的随机分组,这个方式在我们跑多组实验的时候遇到了问题 按用户ID属性计算分组值存在的潜在问题如下 假如一个用户U3,基于该用户ID通过某种随机算法计算得到59,按照随机算法被分配到50%~100%这个区间,此时如果Test1区分AB两组,各50%,那么用户U3应该会被分配到Test1的B组;此时如果又有Test2 区分AB两组,各50%,那么该用户仍会被分配到Test2的B组 最后当我们要对Test1的A组和B组做对比时,假设Test2也会或多或少影响Test1的目标转化,那么就会多了一个Test2的干扰因素,从而两个实验的变量会相互干扰结果,无法评估某个Test 变量的贡献,如下图所示: 
因此这种情况下你只能同时跑一组实验。 2、按照用户ID等属性和实验ID计算随机值 后来,我们采用另外一种分组方案,按照用户ID和实验ID共同决定随机值,这样起到在每个实验中,两组的用户也分别均匀分布在其他实验的各组值中,如下图所示原理,理论上两个实验均设置两组各50%,则样本预计将平衡贴近25% 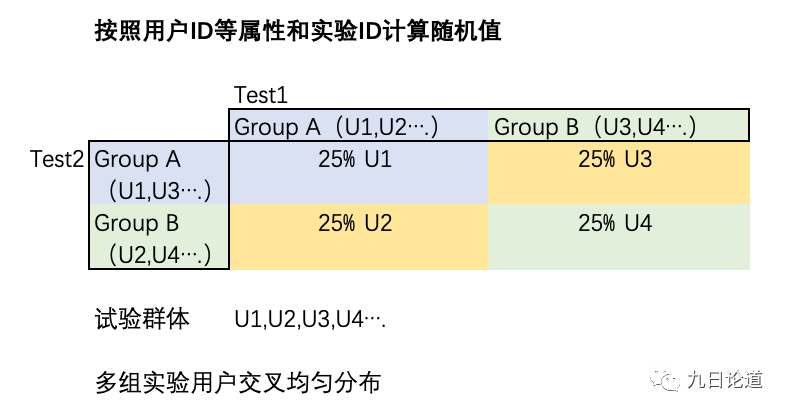
理论上,Test1和Test2就相互不干扰了,因为在分组足够均衡的情况下,Test1 AB各组受其他实验的影响也被均衡了,可以忽略不同变量相互之间的影响 3、另外一种分组方案探索 我们团队还尝试过另外一种方案,这种方式就是把用户按照一个个规定的桶,将用户随机分配好,然后为实验具体组选择某个(几个)桶的用户,会比较强隔离每个实验,互不干扰,相对来说比较方便,但却需要有专人管理和把控实验资源的配置,且样本量要足够大,否则一旦筛选了条件导致样本量不够多,则会面临分组不够用的问题 我身边也有朋友在这么做,这只是分享给大家参考,大家可以结合自己的实际情况来决定 
如果大家选择一些AB 工具则可以不用太担心,人家已经实现了合理的分组,按照说明设置就好了,但在自己实现分组的时候则需要特别留意这块了。 == 实验评估 == 这里我们关注一个重点,如何评估实验结果是否有效,或者说如何评估提升多少才算有效? 关于如何选取评估指标,这个需要大家结合实际业务场景来确定,这个就不介绍了(注意,我们往往不会评估单一指标)。 对于出海来说,尤其是工具类产品,最不陌生的就是免费试用了,这个苹果和谷歌为我们提供了很成熟的产品支持 我就拿这个举例子,也是我们团队亲身经历过的项目 先做个简单假设:上线7天免费试用,能够对收入有提升10%,提高用户付费转化率提高10% 核心评估指标: • 用户付费转化率(7天内,0金额不计算) • ARPU(7天内) 实验分组: A 控制组,默认不曝光 B 实验组,曝光7天免费试用,显示免费试用字样 参考下面数据例子, 
我们可以看到示例中 整个实验周期中,A组有12100个样本参与,B组有12200个样本参与 A组的成功付费转化率为1.65%,B组的成功付费转化率为1.97%(为了简单演示,没有给出置信区间估计) 如果单靠看转化率的变化,我们可以看到B组有些效果,但提升是否真的有显著效果呢? 这就要求我们引入统计显著的概念了,先来看示例中我们计算的结果是95%显著,这个就能极大给我们信心说结果是显著的。 当转化率结果显著,这个意味着实验有胜出组了,然后看ARPU表现,即可大概率确认实验的效果。 这里只举一个指标评估做为例子,实际评估还需要结合实际业务来看,包括评估方案的正向反向效果。 一个小技巧:当我们的运营团队不知道如何分析结果的归因时,采用转化前后的用户行为做差异分析,这样就能大概率做到对结果的归因分析了,关于归因仍为一个大专题,不在这里做详述。 == 统计是否显著概念 == 如果有朋友学过统计学或者接触过类似的概念,相信不会陌生,这里只做下概念普及,为了通俗易懂,有些描述可能也不是特别的科学严谨 统计推断的概念需要有一个【原假设】,这个【原假设】我们一般假设实验的方案不如老方案效果好,然后想办法推翻,以此来坚信我们的实验是有效果 例如这个效果指付费转化率,那么就是说,实验的B组的成功概率(用PB表示)不如实验A组的成功概率(用PA表示)高,即PB <= PA 有了【原假设】,接下来只需要找证据推翻上述【原假设】就可以了 前面实验中PB = 1.97%,而PA=1.65%,PB > PA,这个时候可以推翻原假设吗? 不能确定,因此需要引入统计显著的概念,一般显著度达到95%以上,就可以有足够的信心推翻原假设 这个95%你可以简单理解为PB > PA发生的概率超过95%,这样我们的信心就很足了。 关于显著度的计算这里不深入展开,只是提供大家一个判断依据,对效果的评估要加上这个会比较科学,这样能知道方案上线后有效果的把握程度。 注意:发生概率高,不代表一定会发生,所以要做好上线后随时准备面临结果不如意的心态。 == 别忘了细分实验结果 == 在我们多次跑实验的经验,尤其是对于出海应用,我们面临了很多的国家市场,来自全球各地人付费文化和行为模式是存在差异的,因此我们前期实验选择的群体可能就包含了不同消费特性的人群,因此无论在总体结果是否显著的情况下,我们都应该做更多维度的细分。 这样我们能有效发现那些响应不足或响应后效果差的地区,对策略做出及时的调整。 == 巧妙利用AABB分组 == 这个是我最后想补充的内容 想必大家都会遇到一些波动特别大的指标,类似一些收入指标,那实验出现随机的结果是很可能发生的,这个时候AABB分组策略能给我们提供一些信息 假如我们实验只是简单的分为两组,实际上我们还能够将A组划分成A1,A2,将B组划分成B1,B2组 通过对比组间,如A组和B组的结果来衡量实验效果 还能通过对比A1和A2,或对比B1和B2来确认组内的数据是否稳定,如果组内数据差异过大,而组间差异也表现差异很明显的时候,这个时候就要小心我们前面提到的随机发生的结果 因此AABB分组还够给我们提供更多的实验信息,大家可以去尝试一下。 == 后续 == 由于篇幅问题很多内容无法开展讨论,我们后续有机会再给大家分享。 本篇文章内容篇概念和理论层面多一些,后续系列文章将分享如何实战分析的过程,会结合实际的分析工具,让产品和运营人员也能上手做深入分析。 作者:大Fei 来源:九日论道 |
编后语:关于《从设计到归因 - AB Test 实战心得》关于知识就介绍到这里,希望本站内容能让您有所收获,如有疑问可跟帖留言,值班小编第一时间回复。 下一篇内容是有关《游戏全球化背景下,中小团队如何参与最热赛道竞争》,感兴趣的同学可以点击进去看看。




























































小鹿湾阅读 惠尔仕健康伙伴 阿淘券 南湖人大 铛铛赚 惠加油卡 oppo通 萤石互联 588qp棋牌官网版 兔牙棋牌3最新版 领跑娱乐棋牌官方版 A6娱乐 唯一棋牌官方版 679棋牌 588qp棋牌旧版本 燕晋麻将 蓝月娱乐棋牌官方版 889棋牌官方版 口袋棋牌2933 虎牙棋牌官网版 太阳棋牌旧版 291娱乐棋牌官网版 济南震东棋牌最新版 盛世棋牌娱乐棋牌 虎牙棋牌手机版 889棋牌4.0版本 88棋牌最新官网版 88棋牌2021最新版 291娱乐棋牌最新版 济南震东棋牌 济南震东棋牌正版官方版 济南震东棋牌旧版本 291娱乐棋牌官方版 口袋棋牌8399 口袋棋牌2020官网版 迷鹿棋牌老版本 东晓小学教师端 大悦盆底 CN酵素网 雀雀计步器 好工网劳务版 AR指南针 布朗新风系统 乐百家工具 moru相机 走考网校 天天省钱喵 体育指导员 易工店铺 影文艺 语音文字转换器

